gorm
面向对象编程和关系型数据库,都是目前最流行的技术,但是它们的模型是不一样的。
面向对象编程把所有实体看成对象(object),关系型数据库则是采用实体之间的关系(relation)连接数据。很早就有人提出,关系也可以用对象表达,这样的话,就能使用面向对象编程,来操作关系型数据库。
简单说,ORM 就是通过实例对象的语法,完成关系型数据库的操作的技术,是"对象-关系映射"(Object/Relational Mapping) 的缩写。

想必每个接触go后端开发的都对gorm不会感到陌生,应该是go中的首选orm了,其支持的特性也很全
特性
- 全功能 ORM
- 关联 (Has One,Has Many,Belongs To,Many To Many,多态,单表继承)
- Create,Save,Update,Delete,Find 中钩子方法
- 支持 Preload、Joins 的预加载
- 事务,嵌套事务,Save Point,Rollback To Saved Point
- Context、预编译模式、DryRun 模式
- 批量插入,FindInBatches,Find/Create with Map,使用 SQL 表达式、Context Valuer 进行 CRUD
- SQL 构建器,Upsert,数据库锁,Optimizer/Index/Comment Hint,命名参数,子查询
- 复合主键,索引,约束
- Auto Migration
- 自定义 Logger
- 灵活的可扩展插件 API:Database Resolver(多数据库,读写分离)、Prometheus…
常用的特性标黑
版本
好像现在更新到v2版本了,不过要注意的时候,在项目中import的时候要注意
有些老的项目导入的库地址可能不一样,从而导致有些函数或者类型会不一致
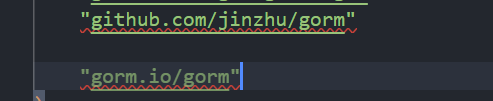
这个是版本1 到 v1.9.16
github.com/jinzhu/gorm
这个是版本2
gorm.io/gorm
之前就由于自动导入的情况,发生了 err.RecordNotFind 互不相等的乌龙事件出现 = =
使用的一些技巧
- 在
DB.Model(&User{})后面加.Debug(),执行的时候会在控制台输出对应的SQL语句,方便对一下逻辑 - 此外,
DB.Model(&User{})和DB.Table("user")的区别在于,Model会调用&User{}类型的TableName方法获取到表名 - 插入多条数据的话尽量用
createInBatches,gorm会把所有的一个batch的value拼接成一条传入,性能会好点 - 反序列化结构体的时候,看的tag是`gorm:"column:name"`,没有字段的话会将字段名驼峰化去表中找对应,如果都没有会报错
First and Find
查询的时候使用First,如果没有命中的结果,会返回err(RecordNotFind),所以需要对err的内容进行判断,而使用Find的时候不会,但是Find的性能会低一些

Exec和Raw的区别
同样是调用存储过程,使用Exec可以成功,但是Raw失败了,用debug一看,Raw压根没有执行这个语句
PART_PROCEDURE = `CALL create_partition_by_day('tgw_oss_global', 'tb_l4_rs_info');`
if err := common.MetaMDB.Exec(PART_PROCEDURE).Error; err != nil {
fmt.Println(err)
return
}
if err := common.MetaMDB.Raw(PART_PROCEDURE).Error; err != nil {
fmt.Println(err)
return
}看了发现,好像一些其他的语句也会出现这种情况
- 自加操作
update projects set likes = (likes + 1) where projectid = xxx - 更新字段为空值
- 本次遇到的情况:调用存储过程
官方文档也没说的很清楚
貌似是
- RAW:一般配合Scan使用,适用于带结果的语句
- Exec:执行不会返回任何item的SQL语句
存在则更新,不存在则插入(upsert)
有时候我们会有这样的需求,对于表中的某一行,如果有一行某个列的值已经存在(唯一标识这个行的记录),那么更新这个行某些字段的值,否则就插入新的一行记录
由于 MySQL 提供了 ON DUPLICATE KEY UPDATE 的能力,我们可以充分利用唯一键的约束,来搞定并发场景下的 CreateOrUpdate。
import "gorm.io/gorm/clause"
// 不处理冲突
DB.Clauses(clause.OnConflict{DoNothing: true}).Create(&user)
// `id` 冲突时,使用map方式更新字段role
DB.Clauses(clause.OnConflict{
Columns: []clause.Column{{Name: "id"}},
DoUpdates: clause.Assignments(map[string]interface{}{"role": "user"}),
}).Create(&users)
// 字段`id`冲突时候,更新指定列
DB.Clauses(clause.OnConflict{
Columns: []clause.Column{{Name: "id"}},
DoUpdates: clause.AssignmentColumns([]string{"name", "age"}),
}).Create(&users)由于冲突行为是唯一键,所以涉及多个字段的话,需要在多个字段上增加联合唯一索引
分页
在分页的时候,有这么一个需求,在查库返回数据的同时,需要反序列数据并同时拿到数据的数量一起返回给前端,实现分页的功能。
燃鹅,这个总数量不能单纯在接收数据后再去看数据的长度,因为这时候往往已经是带着分页的条件去查的数据,数据长度只是一部分(limit 10,Offset 10),而前端要的是数据总数(total),所以要么,开启一个事务,在事务中先查数据,后查count,但是这个显得挺麻烦,于是查了一下
err := db.Model(&TPeople{}).Where("age = ?", 18).
Order("username asc").
Limit(10).
Offset(3).
Scan(&peoples).
Limit(-1).
Offset(-1).
Count(&count).
Error
即可以通过重置条件中的Offset和Limit,并在后面接上count(&total),即可以让gorm同时执行两个语句分别序列化分页范围内的数据并返回数据总数
另外,常见的分页函数
func Paginate(page,size int) func(db *gorm.DB) *gorm.DB {
return func (db *gorm.DB) *gorm.DB {
if page <= 0 { page = 1 } switch { case size > 100:
size = 100
case size <= 0:
size = 10
}
offset := (page - 1) * pageSize
return db.Offset(offset).Limit(pageSize)
}
}
db.Scopes(Paginate(0,10)).Find(&users)
db.Scopes(Paginate(1,20)).Find(&articles)其中,db.Scopes()可以调用通过闭包函数func (db *gorm.DB) *gorm.DB保存的一些重复的逻辑,常见的如
- 分页
- 固定条件的查询(如等值)
- 动态表或动态分区
硬删除和软删除
如果model中的结构体嵌套了gorm.BaseModel或者在字段中手动增加了DeletedAt gorm.DeletedAt,那么查询的时候会查询DeletedAt IS NULL的记录,而默认的删除则是Update DeletedAt为操作的时间,如果想要在保留这个字段的前提下进行硬删除,则可以加Unscoped()
db.Unscoped().Delete(&User{}, id)